Metadata harvesters¶
Project-level Metadata¶
The Project-level Metadata level is related to the main CAGS interface website from which metadata are harvested through the online submission form. It collects metadata (derived and expended from Dublin Core metadata) which incorporates a number of descriptive and resource discovery focused elements describing either a scientific communication, a notebook and a dataset independently or jointly.
File-level Metadata¶
The File-level Metadata is a gui designed to help with the initial preparation of one geophysical dataset. Starting from one or multiple input directories, a cleanly structured output directory is generated (without deleting any input files). Generate suitable metadata from user input and write this metadata into the directory structure, making it ready for further distribution.
geophysical Metadata Management using a Juypter Notebook
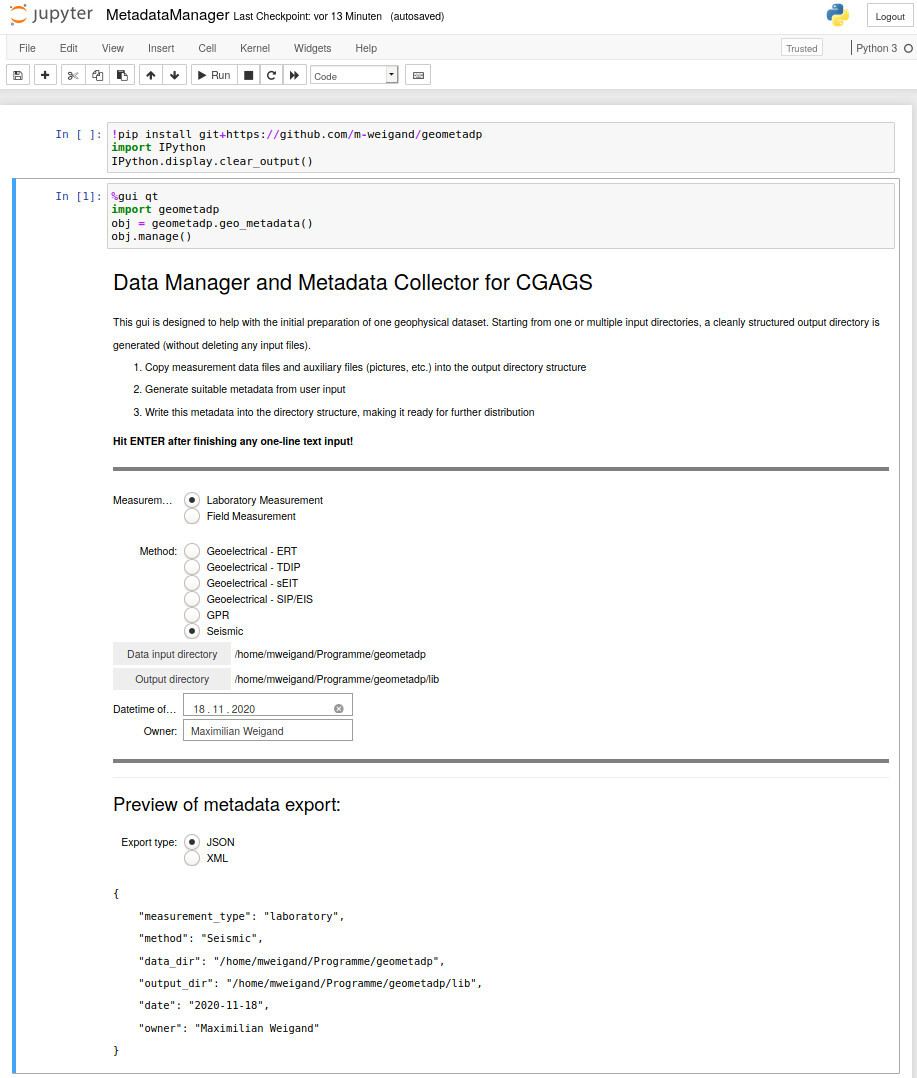
Fig. 1 Geophysical Metadata Management using a Juypter Notebook <https://github.com/m-weigand/geometadp.git>
Data management¶
Requirement to publish to the CAGS¶
- Make sure you have the publication rights for the data, using dedicated repositories such as Zenodo or other licensing schemes (e.g., Creative Commons licenses; https://creativecommons.org/share-your-work/licensingtypes-examples/);
- All datasets must include a README in the root directory;
- Adding metadata about your dataset is required.
Data package linter¶
Workflow for preparing a dataset¶
- Sort data into subdirectories.
- Write an ASCII ‘Readme’ file which states the basic characteristics of the datasets (settings, procedures, etc);
- Identify the used data formats and check if they are documented/importable by available free software;
- Formulate a JSON formatted metadata file following one of our metadata standards using geometadp
- Upload the dataset to a data repository;
- Register with CAGS (using the form or by opening a tasks tracker on the github repository e.g. via github-issue).